
type
status
category
date
slug
summary
tags
icon
Last edited time
May 21, 2023 07:57 AM
一、直接插入排序
每次将一个待排序的序列插入到一个前面已排好序的子序列当中
使用到了
顺序查找图片演示
前面是有序的,逐步逐步将后面的插入到前面去

实现步骤
初始 是一个已经排好序的子序列 对于元素插入到前面已经排好序的子序列当中
- 查找出 在 中应该插入的位置
- 将中所有元素全部后移一个位置
- 将复制到
例子
就类似,打扑克打时候,理牌的过程,把牌插入前面已经整理好了的牌内,的过程
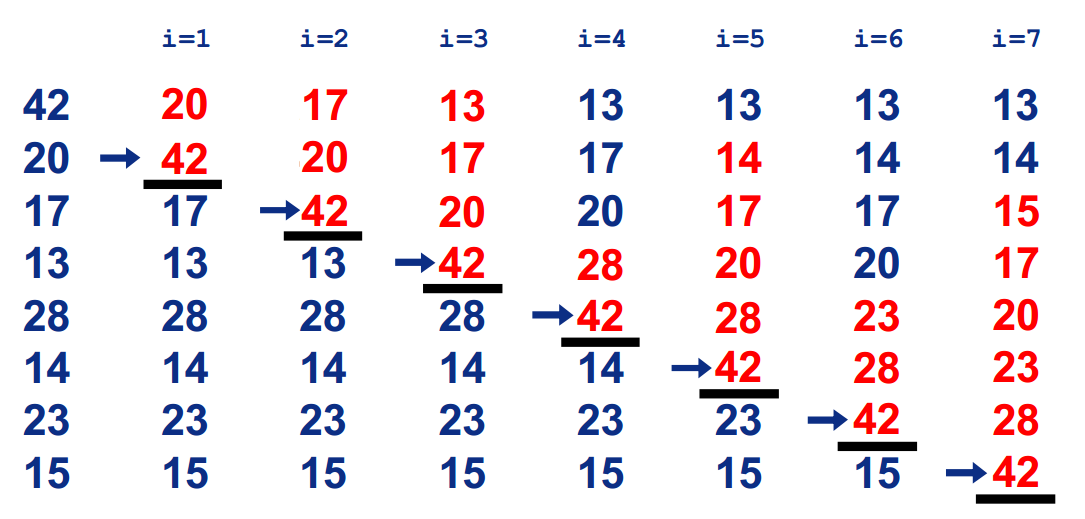
- 图片来自菜鸟教程
关于选择排序的参数
1、时间复杂度
最好 所有元素有序,一开始就是有序的
平均
最坏 想要递增的,结果是递减的序列
2、空间复杂度
3、是否稳定
稳定
4、适用于何类型存储
顺序存储和链式存储
5、优缺点
优点 : 稳定,相对于冒泡排序与选择排序更快;
缺点 : 比较次数不一定,比较次数越少,插入点后的数据移动越多,特别是当数据总量大的时候;
代码实现
C++:
二、折半插入排序
折半插入算法是对直接插入排序算法的改进,排序原理同直接插入算法
使用到了
折半查找,折半查找相比直接插入排序的顺序查找,效率更高关于折半查找
又称二分查找,仅适用于==有序==的==顺序==表(存放数组中 折半査找只适用于顺序存储,且要求序列一定有序。
1、算法思想
首先将给定值 key 与表中中间位置元素的关键字比较
若相等,则返回该元素的位置
若不等,则在前半部分或者是后半部分进行查找
2、代码实现
插入排序实现步骤
见代码实现
关于折半插入排序的参数
1、时间复杂度
2、空间复杂度
3、是否稳定
稳定——不影响相对顺序,相同的话会插入到后面
4、使用于何类型存储
顺序存储
折半插入代码实现
C++:
观察他们间的小差别
这是插入排序:
这是折半查找:
基本上就是在直接插入排序移动元素前,插入了一个折半查找,提升查找效率
其中的小区别,就是:折半查找是找到key值相等的那个元素的位置,而在折半插入排序中,使用到折半查找的目的,是找到应该插入的位置,并不需要key值相同
所找到的位置就是
high+1而为什么是high+1,而不是low+1,或者mid+1呢?
实际上用
low也是可以的
观察中间的while循环,在最后一次循环的时候的时候,low == high
此时,low , high , mid 三者是同一个值
两种情况(1)如果mid的key 大于我们要插入的值的key,那么情况是
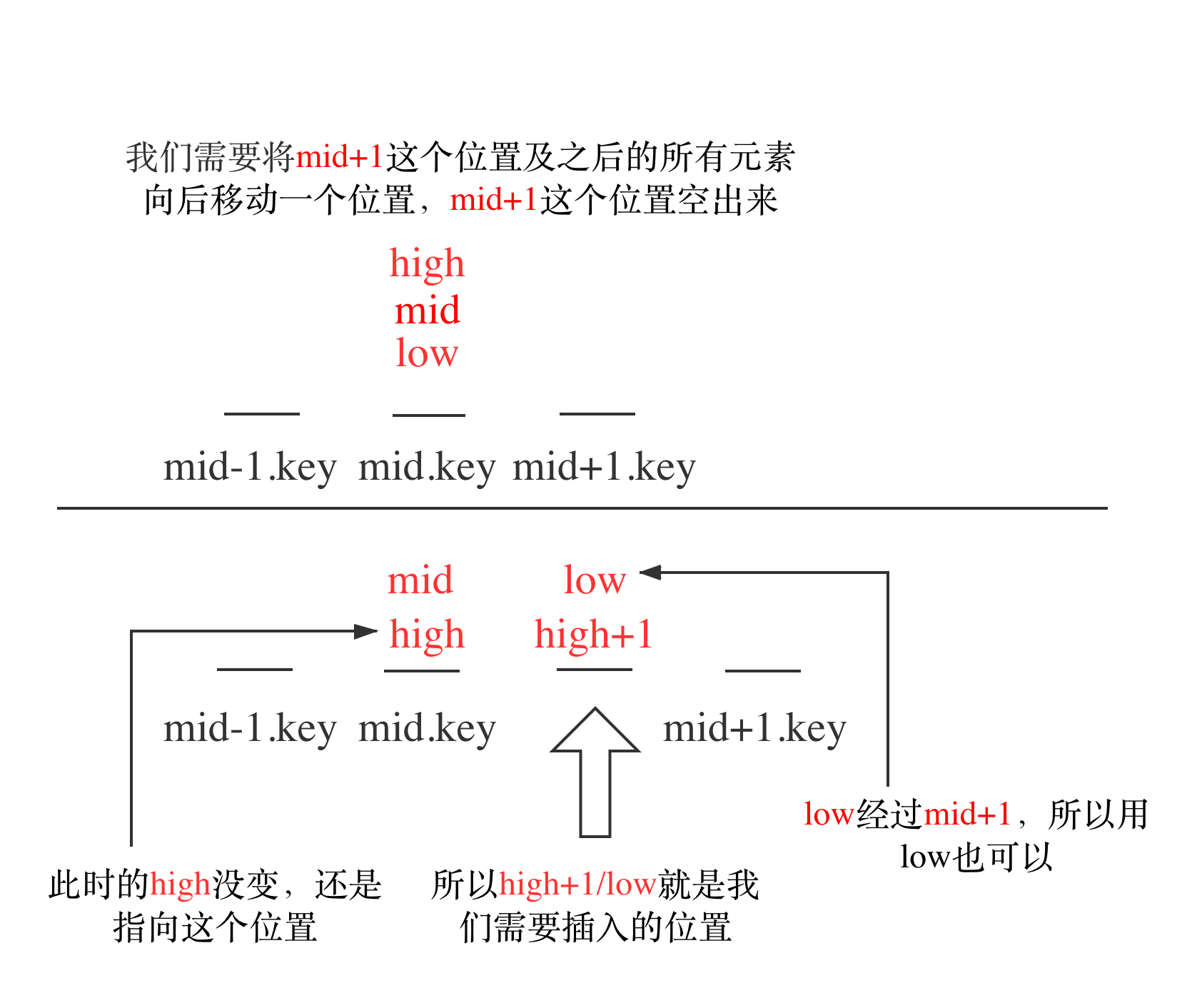
(2)如果mid的key 小于我们要插入的值的key,那么情况是
- 作者:Jimmy Huang
- 链接:https://huangjihao.com/da96d385-c971-4d1f-8d2d-83304d876dd2
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。